The Protocol Layer for Agent Systems (Model Context Protocol)
Part 12 of the AOD Series | Part II: The ADLC | Integration Patterns
At a large financial services company, I inherited a problem that nobody wanted to own. We had over 40 different Customer Identity and Access Management (CIAM) tools scattered across the enterprise. Every application had a different login. Customers were confused, IT was drowning in complexity, and security couldn't get a clear picture of identity risk.
The ask wasn't just cleanup. I was tasked with building an internal CIAM platform, a product that business units would adopt and be charged back for. That meant I wasn't just consolidating tools. I was competing with the open market. If my platform wasn't better and cheaper than what a business unit could buy on its own, they had no reason to use it.
I formed a consortium of identity experts from every business unit and started with requirements, not vendors. If they helped build the scorecard, they were more likely to trust the result. We interviewed the top 10 vendors, narrowed it to three, ran half-day proof-of-concept sessions with executives, and reached a consensus. Then we hit a wall. Data residency laws required that customer data reside within certain countries' borders. A third of our business units operated in those countries. The centralized architecture we had selected was a non-starter for them.
Rather than accept that a third of the organization would be left behind, we adapted. Local identity stores for regional compliance, federated through the SaaS platform, so developers still have one API. Data could live where the law required it, and developers didn't have to care. The business unit that had fought us hardest did a complete reversal. Four million customer accounts on one platform within the first year.
That was platform consolidation in the identity world. I see the same movie playing out today in every team building agent systems. Every tool integration is custom. GitHub? Custom integration. Database? Different custom integration. Cloud storage? Another one entirely. The problem isn't that the tools don't work. The problem is that every connection is bespoke, every integration is fragile, and nobody has a complete picture of what's connected to what.
The Model Context Protocol (MCP) is the standardization moment for agent integration. One protocol. Every tool is accessible through the same interface. Chapter 3 introduced MCP as "the REST moment for agents." Chapter 4 showed MCP servers as dependency injection. This chapter goes deep on the protocol mechanics, the design decisions practitioners face, and the patterns that make MCP integration work at scale.
Three questions drive this chapter. When do you use MCP versus a skill versus memory? (This is the community's number one confusion right now.) How do you scope and design MCP tools for reliability? And what does the protocol landscape look like when agents need to talk to tools AND to each other?
The Recipe, the Kitchen, and the Journal
MCP is one of three mechanisms for extending an agent's capabilities. Practitioners confuse them because they overlap. Let me draw the boundaries.
Skills are the Recipe. A skill is a markdown file (or a folder of files) that loads domain knowledge into the agent's context. It teaches the agent how to think about a domain. What conventions to follow? When to apply certain patterns. Skills shape reasoning. They don't connect to external systems. In OOP terms, skills are method implementations. The business logic and decision rules that live inside the class.
MCP is the Kitchen. MCP servers enable DOing things. Query a database. Call an API. Persist a cross-project learning. MCP servers run as separate processes and provide tools, resources, and prompts through a standardized protocol. In OOP terms, MCP servers are interfaces and dependency injection. The capabilities injected at configuration time, not coded into the class itself.
Memory is the Journal. Memory captures what the agent discovers through use. Code patterns that work. Recurring issues in the codebase. Conventions that the team follows but never documents. Memory evolves over time without human editing. In OOP terms, memory is accumulated state. What the object has learned through execution.
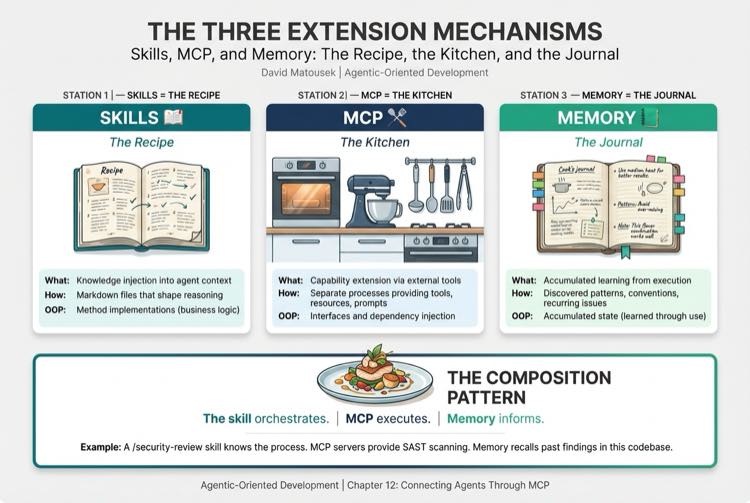
The most powerful architecture isn't any one of these in isolation. It's the composition pattern, a skill that orchestrates MCP tools, informed by memory. The skill provides the workflow knowledge and decision framework. MCP tools provide the execution capabilities. Memory provides the context about what has worked before.
Here is a concrete example. A /security-review skill knows the review process, including which scans to run, what severity thresholds to apply, and when to escalate. MCP servers provide the static analysis scanning, dependency checking, and infrastructure-as-code validation capabilities. Memory tells the agent that this particular codebase has a history of SQL injection findings in the data access layer. The skill orchestrates. MCP executes. Memory informs. This is the security review pipeline from Chapter 3, now explained as a composition pattern. And in Chapter 4's terms, the skill is the class definition. The MCP servers are the injected dependencies. The running agent is the instantiated object.
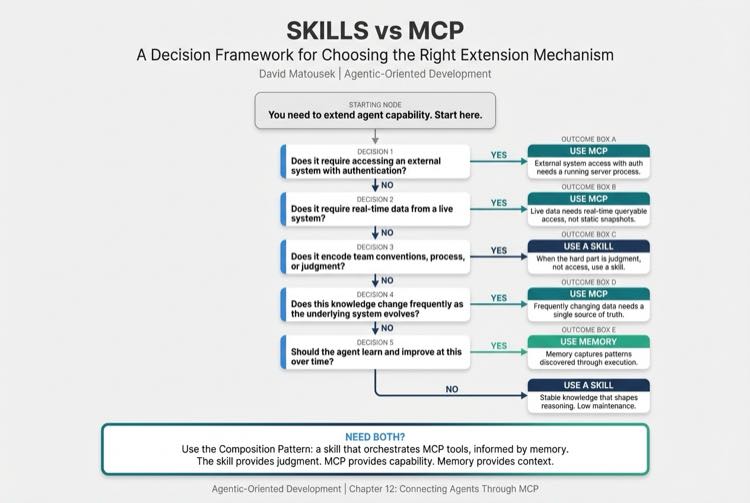
But how do you know which mechanism to reach for? I like to frame it as five questions.
| Question | If Yes | If No |
|---|---|---|
| Does it require accessing an external system with authentication? | MCP | Could be either |
| Does it require real-time data from a live system? | MCP | Skill (static knowledge is fine) |
| Does it encode team conventions, process, or judgment? | Skill | Likely MCP |
| Does this knowledge change frequently as the underlying system evolves? | MCP (single source of truth) | Skill (stable, low maintenance) |
| Should the agent learn and improve at this over time? | Memory | Skill or MCP |
When Armin Ronacher moved Sentry's MCP server to a skill, his reasons were practical. The MCP server consumed around 8,000 tokens out of the box. The underlying API changed its query format without notice, breaking his workflows. He preferred having the tool under his control. In AOD terms, the integration was really knowledge injection (how to interpret error reports, which queries to run) rather than capability extension. When the hard part is judgment, not access, use a skill.
And before building an MCP server, ask whether a bash script inside a skill would suffice. MCP adds process management, token overhead, and maintenance burden. The threshold for MCP is that the integration is called frequently, requires typed schemas for reliability, serves multiple agents or clients, or needs authorization and discovery features. If none of those apply, keep it simple.
Tools, Scope, and Less Is More
MCP tool design is the single biggest factor determining whether agents use tools correctly or collapse into confusion.
The protocol defines three primitives, each with a different control model.
| Primitive | Controlled By | When to Use |
|---|---|---|
| Tools | Model (LLM decides to call) | Agent needs to DO something |
| Resources | Application (host decides to include) | Agent needs to SEE data |
| Prompts | User (human selects explicitly) | Structured interaction templates |
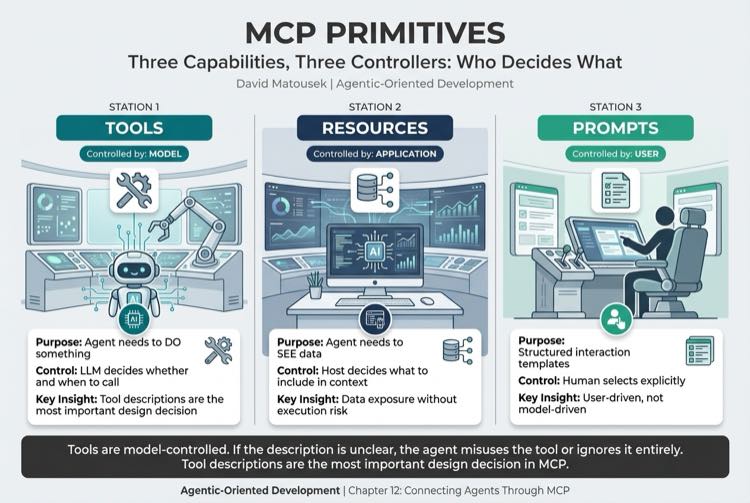
Why does this matter? Tools are model-controlled. The agent decides whether and when to call them based on tool descriptions. If the description is unclear, the agent misuses the tool or ignores it entirely. Tool descriptions are the most important design decision in MCP.
And there is a hard limit on how many tools an agent can handle. From what I have seen, accuracy degrades significantly as the tool count increases, with overlapping descriptions making it worse. GitHub reduced the number of Copilot tools from 40 to 13, improving both accuracy and latency. Block rebuilt their Linear integration three times, reducing it from over 30 tools to 2, as documented on their engineering blog. The industry consensus is converging on no more than 10 to 15 tools active at any one time. If you are loading more than that, your agent is probably confused.
The token overhead is real and often surprising. Community reports document cases where three MCP servers (GitHub, a browser automation tool, and an IDE connector) consumed 143,000 of a 200,000-token context window before the agent read its first user message. I remember my first encounter with this problem. I configured what felt like a reasonable set of servers, then watched my agent struggle with a task it should have handled easily. MCP tool schemas are loaded upfront. Every tool description eats context. This connects directly to Chapter 2's context management. Tool pollution is context pollution at the capability layer. Same discipline, different layer. Load what you need, when you need it.
One mitigation that has emerged is tool search, in which tool definitions are loaded on demand rather than upfront. This approach achieved an 85% token reduction in testing. The principle is the same as context management. Defer loading until you actually need it.
When designing MCP tools, the VOICE principles from Chapter 3 apply directly.
- Visible. Clear descriptions that tell the agent exactly what the tool does, what it returns, and when to use it. Vague descriptions produce vague tool usage.
- Outcome-oriented. Tools should map to outcomes, not implementation steps. "Create a pull request" rather than "run git push and then call the API."
- Isolated. Each tool gets the minimum permissions needed. Least privilege at the tool level.
- Composable. Fine-grained tools that chain into workflows. Not one monolithic "do everything" tool.
- Error-aware. Two-layer error handling. Protocol errors (the connection failed) and tool execution errors (the query returned an error) are different failure modes requiring different responses.
Chapter 3 introduced VOICE as the design framework for agent tools. MCP provides the protocol for delivering those tools. VOICE is the design standard. MCP is the delivery standard. They complement each other.
One more point on tool design. The MCP spec defines annotations like readOnlyHint, destructiveHint, and idempotentHint (indicating the tool can be called repeatedly with the same result). But the spec itself warns that tool annotations should be considered untrusted unless obtained from a trusted server. This is a security boundary, not a reliability guarantee. Don't build your safety model on hints from servers you haven't audited.
MCP as Dependency Injection
Chapter 4 introduced a key insight. "MCP servers work like dependency injection. You configure the connection once, and agents receive the tools at runtime." This section extends that from an analogy into a trust boundary you need to understand.
Consider a testing agent configured with a browser automation MCP server. It can run browser tests. Swap that server for a different browser automation tool, and the same agent runs tests through a different engine. The agent's instructions don't change. The injected capability does. A security review agent with static analysis, dependency scanning, and infrastructure-as-code MCP servers gets a comprehensive review. Remove the infrastructure server, and the same agent does code-only reviews. The configuration determines the capability.
The server isolation principle makes this work. MCP servers can't see the conversation or other servers. Each server receives only the contextual information necessary for its operations. This is encapsulation at the protocol level. Roots provide filesystem scoping, where clients define file:// URIs that bound where servers can operate, implementing least privilege at the filesystem level.
The wiring pattern is identical to dependency injection in any modern framework. In OOP, container.register(IEmailService, SmtpEmailService). In MCP, "mcpServers": { "email": { "command": "smtp-mcp-server" } }. Swap the binding, swap the behavior.
But there is a key difference. In traditional dependency injection, the container runs trusted code inside your process. In MCP, injected dependencies are external processes that may run third-party code. From my experience wiring these configurations across multiple projects, this is the insight that changes how you think about MCP. The wiring pattern is the same. The trust model is not.

Dependency injection tells you how capabilities get wired. But what about the knowledge those capabilities produce? That is where MCP's role shifts from plumbing to something more interesting.
Practitioner Knowledge Through MCP
The Three-Layer Memory Model organizes agent memory by scope and persistence. Layer 1 is session context (volatile, single conversation). Layer 2 is project knowledge (skills, repo artifacts, discovered conventions). Layer 3 is Practitioner Knowledge, cross-project learnings that transcend any single repository and persist across the practitioner's entire body of work. MCP is what makes Layer 3 queryable.
Why is the Practitioner Knowledge an MCP use case and not a skill? Three reasons.
First, it contains dynamic, cross-project data that changes as the practitioner works. MCP provides real-time queryable access. A skill would be a static snapshot that goes stale.
Second, it needs to be accessible to any agent in any project. MCP's client-server model provides exactly this. A skill would need to be copied into every project's repository, and you would have a synchronization problem immediately.
Third, it benefits from typed search operations. Semantic search, tag-based browsing, temporal queries ("what did I learn about rate limiting in the last three months?"). MCP's tool schema makes these explicit and reliable.
But it also needs a skill layer. A skill that teaches agents what the Practitioner Knowledge contains, when to query it, and how to interpret results. This is the composition pattern in action. The skill provides the judgment ("before starting a new project, check the Practitioner Knowledge for relevant governance patterns"). The MCP server provides the capability ("search the Practitioner Knowledge for patterns matching 'financial services compliance'").
From what I have seen building this kind of cross-project knowledge layer, the biggest challenge isn't the technology. It's about deciding what deserves promotion from project-level to practitioner-level knowledge.
The Three-Layer Memory Model, now with mechanisms.
| Memory Layer | Mechanism | Scope |
|---|---|---|
| Layer 1: Context | Working memory (prompts, outputs) | Session |
| Layer 2: Project Knowledge | Skills (authored) + Memory (discovered) + Repo artifacts | Repository |
| Layer 3: Practitioner Knowledge | MCP server (cross-project, queryable) + Memory (user-scoped) | Practitioner / Organization |
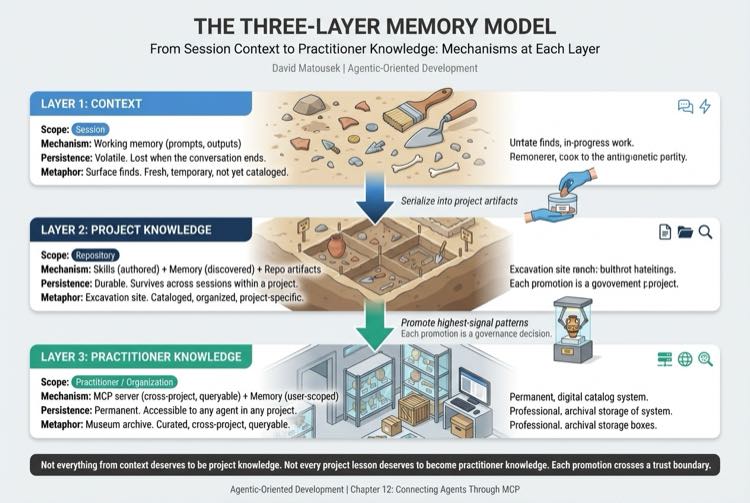
The distillation flow, the process of promoting high-signal learnings from session context to project knowledge to cross-project knowledge, runs through these mechanisms. Context (volatile) gets serialized into Project Knowledge (skills, repo artifacts). The highest-signal patterns get distilled into the Practitioner Knowledge (MCP server). Each promotion crosses a boundary. Each boundary is a governance decision. Not everything from context deserves to be project knowledge. Not every project lesson deserves to become cross-project knowledge. Organizations with data classification policies should apply the same rigor to knowledge distillation that they apply to any other data promotion across trust boundaries.
Chapter 13 will introduce the Context Continuity Score, a measure of how well future agents can pick up where the last one left off. The Practitioner Knowledge MCP server is the infrastructure that makes high continuity scores possible across projects, not just within them.
That governance question, what to promote and what to leave behind, becomes even more urgent when you consider what happens when those boundaries aren't enforced.
MCP Security as a Governance Problem
Here is what the MCP specification itself says about security. "MCP itself cannot enforce these security principles at the protocol level." Security is delegated to implementors. That is both a strength and a risk. Flexibility for diverse deployment contexts on one hand. Inconsistency across the ecosystem on the other.
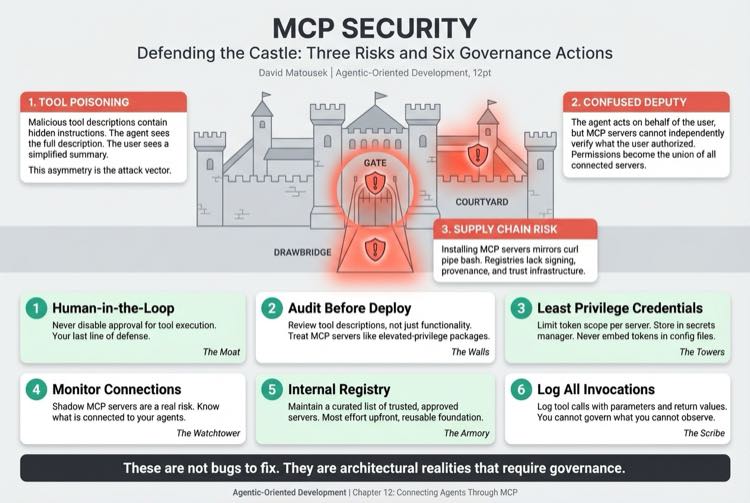
Three risks every practitioner should know.
Tool poisoning. Malicious tool descriptions contain hidden instructions that direct the agent to exfiltrate data or take unauthorized actions. The agent sees the full description, including hidden content. The user sees a simplified UI summary. This asymmetry between what the agent reads and what the human sees is the attack vector.
The confused deputy. The agent acts on behalf of the user, but the MCP server can't independently verify what the user authorized. The agent's effective permissions become the union of all connected MCP server capabilities. Individual servers can't verify which specific actions the user intended. The MCP specification's proposed OAuth 2.1 authorization framework aims to address this, though adoption remains early.
Supply chain risk. Installing MCP servers mirrors the "curl pipe bash" pattern that the security community has warned about for years. Registries lack the signing, provenance, and trust infrastructure that mature package ecosystems have built over decades. Roughly 100 of 3,500 servers in one major registry are linked to non-existent repositories.
These are not bugs to fix. They are architectural realities that require governance. The Governance Triad from Chapter 2 and Chapter 8 applies directly.
- The PM defines which MCP servers are approved for the project
- The Architect designs the server configuration and scope boundaries
- The Team Lead ensures developers follow the approved server list
I have seen a version of this problem before. At a previous role, I discovered that development teams were storing secrets (API keys, database credentials, service tokens) in configuration repositories where they didn't belong. Broad access permissions, no rotation, no auditing, and nobody else saw it as urgent because "that's how we've always done it." I escalated to the CISO, drove a policy change, built a KRI to measure remediation, and, within six months, eliminated the risk across the enterprise. Shadow MCP servers feel like the same pattern. Developers connect servers individually, without team knowledge, because it makes their work easier. Nobody has a complete picture of what's connected. The risk is invisible until you look for it.
What to do today. The highest-impact action is the simplest.
- Never disable human-in-the-loop approval for tool execution. This is your last line of defense against tool poisoning and confused deputy attacks.
- Audit MCP servers before deployment, just as you would audit any package with elevated privileges. Review the tool descriptions, not just the functionality.
- Apply least privilege to credentials. Limit token scope per server, store credentials in a secrets manager with automated rotation, and never embed tokens in configuration files. A GitHub server that only needs read access should not get write permissions.
- Monitor what servers are connected to your agents. Shadow MCP servers (servers connected by individual developers without team awareness) are a real risk.
- Maintain an internal registry of curated, trusted servers. This takes the most effort up front but creates a reusable foundation for every project.
- Log all tool invocations, including parameters and return values, for audit and forensic review. You can't govern what you can't observe.
The companion infographic for this chapter provides a worked configuration example that shows how these governance actions map to a real server setup, including scope boundaries, tool counts, and credential policies.
The OWASP MCP Top 10 project, currently in beta, deserves comprehensive treatment. That treatment belongs in Securing Agentic Systems (Book 2 of this series), where we go deep into the attack vectors, compliance implications, and enterprise security architecture. This chapter flags the governance reality. Book 2 provides the security blueprint.
Why This Matters Now
The question isn't whether to use MCP. The question is when MCP is the right mechanism versus a skill, how to scope your tools so agents use them correctly, and what governance you wrap around the protocol to keep it secure. Get those decisions right, and MCP becomes the integration layer that makes your agent systems composable, portable, and production-ready.
That is what this chapter delivered. But MCP does not stand alone. Every pillar in this series, from context management to tool design to knowledge engineering, depends on a standard protocol connecting agents to their tools, their data, and their accumulated knowledge. MCP is that protocol. The skill orchestrates. MCP executes. Memory informs. Without the connective tissue, the composition pattern stays theoretical.

The ecosystem backing this model has moved past experimentation. Thousands of MCP servers span registries and marketplaces, with 97 million monthly SDK downloads per Anthropic's project metrics. The Agent-to-Agent (A2A) protocol reached v1.0, with more than 100 partner organizations. Both are now under the Linux Foundation's governance umbrella. This is production infrastructure.
Forty CIAM tools taught me that. One protocol is doing it again.
What's Next
Part II is now complete. You can plan, orchestrate, evaluate, test, persist knowledge, and connect agents through MCP. But how do you know if it's working?
Chapter 13 introduces AURA, the Agentic Utilization and Reliability Assessment, with five metrics for measuring agentic development effectiveness. It captures the cost discipline, knowledge quality, and governance boundaries that Part II taught you to build.
The five skills are in place. The integration protocol is understood. Now we measure.