Part 9 of the Agentic-Oriented Development series
I was head of Enterprise DevSecOps at a large financial services company when the Board of Directors launched a three-tier global Key Risk Indicator program in January 2021. One Tier 3 KRI for application security landed in my lap. Cyber security had never had a metric included in the Enterprise KRIs before. Getting this one in was a huge recognition step for a team in a growth phase I was part of, going from 40 people to 400. I felt great about it.
The metric itself was straightforward. Each BU would remediate 90% of critical and high open-source vulnerabilities within 30 days of discovery. I owned the measurement and reporting, and the remediation belonged to the BUs. Our SCA tool was already being rolled out across the enterprise and gave us the monitoring. A cross-functional working group of seven people ratified the target. The group was me, a Global Program Manager, and the DevSecOps lead from each of our five major business units. Every month, I published the results to the entire global audience.
Four of the five BUs onboarded quickly and hit the target with no problems the first year. The metric was easy enough for them that we moved it to 95% the following year. One BU could not get above 80%, no matter how they tried.
After the BU missed the number three months running, we engaged directly. There was no judgment involved. Their DevSecOps lead was working the problem, and our job was to figure out what we had not yet understood about what was getting in their way.
We walked their portfolio with them and uncovered a variety of reasons. Some of what was lighting up in the report were legacy applications that should have been retired already. Others were live applications that needed specific engineering help their team was not staffed to provide on their own. We gave them that help, and in less than four weeks, we had them above 90%.
That KRI was an eval loop before I had the vocabulary for it. We evaluated quality, debugged issues, changed behavior, and repeated the cycle. The tempo is different, monthly KRIs run on a calendar while agent loops run in seconds, but the architecture is identical.
The AI Evals Flywheel I introduced in From Prompt Engineer to Agentic Engineer was deliberately introductory. Orchestration promised this chapter would show how evaluation becomes control flow, not just quality checking. The agents who build also need agents who judge.
Here is where that promise gets delivered.
The Core Insight: Evals as Control Flow
In traditional programming, if/else and while loops control program flow based on deterministic state. You check a condition. It is either true or false. The program branches accordingly.
In agentic systems, evals serve the same architectural purpose.
Think about it. while (!condition) maps directly to "run until the eval passes." if/else branching maps to eval-based routing, where results determine whether output proceeds to production, gets retried, or escalates to a human reviewer. The eval is the condition check. The loop is the correction cycle.
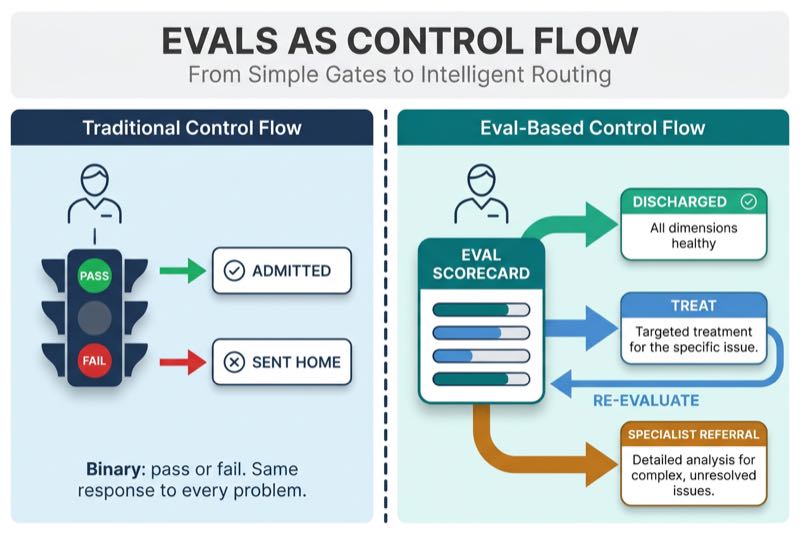
Why does this matter for agents specifically? Because LLM execution is non-deterministic. As Birgitta Bockeler describes in "Context Engineering for Coding Agents," context engineering improves the probability of useful results, but as long as LLMs are involved, you can never be certain of the outcome. Deterministic code doesn't need eval loops. Probabilistic execution does.
This is what I call the probabilistic ceiling. It is the structural limit that makes evals architecturally necessary rather than nice-to-have QA. Context engineering and good prompts improve the odds. They cannot guarantee results. The ceiling is why evals exist as control flow, not just measurement.

I learned this lesson in my DevSecOps work years before I applied it to agents. At a large financial services company, we stopped trusting developer self-reports about security compliance and started scanning actual source code repositories directly. We went from an 80% reported compliance rate to measuring ground truth, and ground truth told a different story. Within a year, actual compliance exceeded 90% across business units. Evals must measure what actually happens, not what people say happens.
From conversations with engineering leaders across my network, the pattern is consistent. AI usage across developer workflows is climbing, but full delegation to agents remains rare. That gap isn't a skill problem. It is an eval coverage problem. Teams don't trust agents with full delegation because they can't measure whether the output is good.
And here is the statement I want you to sit with. If evals are becoming control flow, then whoever designs the eval is shaping the system's behavior whether they realize it or not.
From Single Evals to Multi-Dimensional Scorecards
If eval design shapes system behavior, then a single pass/fail check is not much of a system. It is like checking if a bridge can hold weight without asking how much weight, where the stress concentrates, or what happens when it fails.
A well-designed eval system is a multi-dimensional scorecard. I find it useful to think about four properties that separate useful scorecards from pass/fail traps.
A useful scorecard separates failure modes. Technical accuracy, voice consistency, and reader value fail in fundamentally different ways. A factually incorrect claim is not the same kind of failure as an off-brand tone.
It also weights by severity. Should a typo carry the same weight as a factual error? Of course not. But a binary pass/fail eval treats them identically, obscuring the failures that actually matter.
The third property is what makes the scorecard control flow. It routes to correction paths. Which dimension failed determines which loop to enter, and a technical accuracy failure needs an entirely different correction path than a voice consistency failure.
Finally, a good scorecard involves different evaluators. As Anthropic's engineering team describes in "Demystifying Evals for AI Agents," there are three grader types, each with different strengths. Code-based graders are fast, objective, and reproducible, but brittle when valid variations exist. Model-based graders are flexible and handle nuance, but they introduce their own non-determinism and need calibration.
Human graders remain the gold standard for quality judgment, but they are expensive and slow. A mature eval system combines all three, matching grader type to eval dimension. This creates a dependency worth naming. If you cannot trust your graders, you cannot trust your control flow. A compromised grader is equivalent to a compromised access control check. An attacker who can influence a model-based grader can silently redirect your correction routing. Part V addresses eval integrity as a security architecture decision.
Here is what a practical scorecard looks like when you put all four properties together.
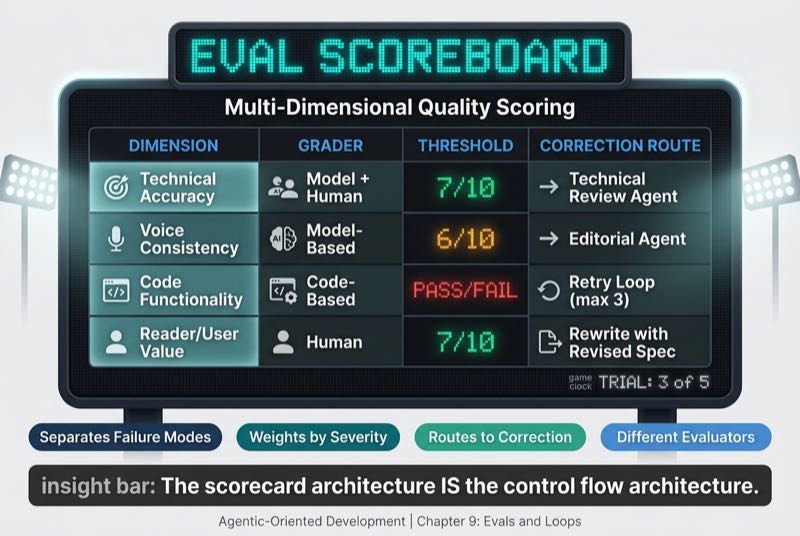
The dimensions, thresholds, and routes will differ for every team. The architecture stays the same. Each row is a potential branch in your control flow.
Now connect this to the Governance Triad from Chapter 8. Who decides what gets tested? The PM Agent validates "is this the right thing to measure?" The Architect Agent validates "is this technically measurable?" The Team Lead Agent validates "is this actionable by the team?" When the same team that builds the agent also defines what "good" looks like without external checkpoints, you get blind spots baked into the evaluation.
The scorecard architecture IS the control flow architecture.
Polymorphic Correction Agents: Routing Failures to the Right Specialist
Polymorphic correction means one correction interface with many specialist implementations, selected at runtime based on what specifically failed. This is polymorphism from Chapter 5 applied to correction.
In traditional code, you write if (failed) retry(). Same correction for every failure. In agentic systems, the eval scorecard becomes the dispatch mechanism. If technical accuracy scores below threshold, route to a technical review agent. If voice consistency fails, route to an editorial agent. If both fail, trigger a compound correction workflow.
The eval scorecard becomes the polymorphic dispatch table.
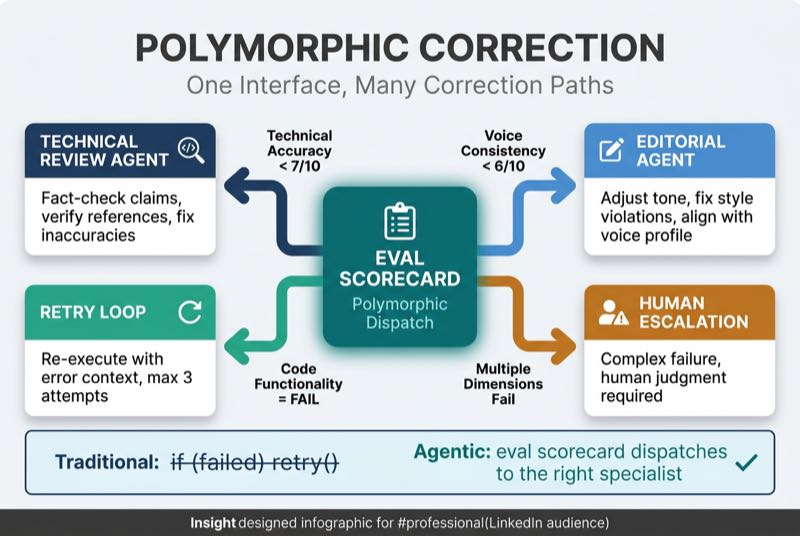
This unlocks targeted correction at scale. A voice consistency failure goes to editorial review, not technical review. Minor inaccuracies auto-correct through retry loops. Major factual errors escalate to human review. Multiple dimensions failing simultaneously triggers specialized workflows that address each dimension in the right order.
I keep coming back to the KRI story because the pattern is identical. When that struggling business unit fell behind on the enterprise KRI, we didn't send them the same generic remediation plan we sent everyone else. We engaged their specific business partner. We identified their specific bottleneck. We applied a targeted fix designed for their situation. That is polymorphic correction in action, years before I had the vocabulary for it. One interface ("get this unit back on track"), multiple correction paths, selected based on what specifically went wrong.
There is also a complementary pattern worth naming. Agents can evaluate their own output before returning it, catching obvious problems before they ever reach an external grader. I have seen this reflective execution pattern save entire correction cycles when an agent catches its own factual errors internally. The tradeoff is straightforward. More self-reflection means higher token cost per task but fewer external corrections downstream. Chapter 10 covers the human version of this pattern, where the developer sitting with the agent becomes the implicit eval.
Anthropic's Eval Framework: A Shared Vocabulary
The scorecard gives you structure. But before building eval infrastructure, teams need shared language for the components involved. Anthropic's engineering team provides five core components that I have found useful as a reference vocabulary.
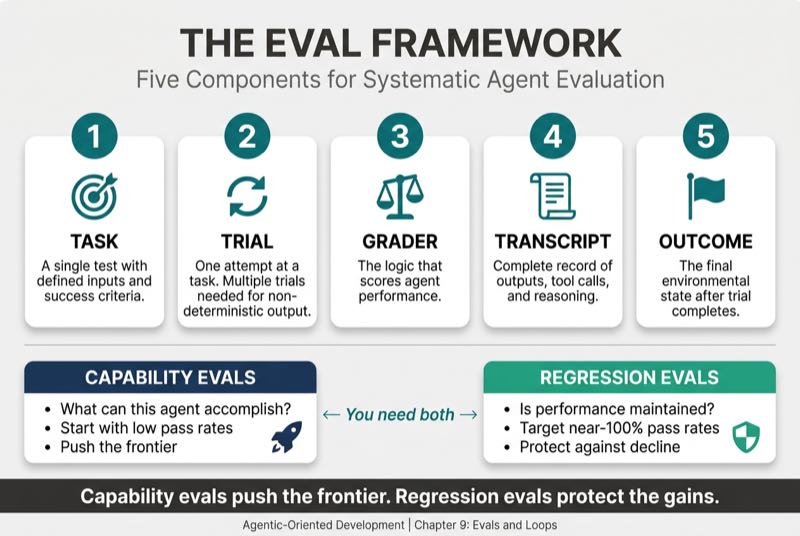
Each row in your scorecard is a Task. Every time the agent runs, that is a Trial. The Grader enforces the threshold you set for each row.
Two distinctions from this framework deserve emphasis. First, capability evals ask "what can this agent accomplish?" and start with low pass rates. Regression evals ask "is performance maintained?" and target near-100% pass rates. You need both. Capability evals push the frontier. Regression evals protect against decline.
Second, non-determinism demands its own metrics. Can the agent ever get this right? That is pass@k, the likelihood of at least one correct solution across k attempts. The optimistic view. Will it get it right every time? That is pass^k, the probability that all k trials succeed. The pessimistic view. In both notations, k is the number of attempts. The @ means "at least one success in k tries." The ^ means "success in every one of k tries."
These aren't abstract distinctions. The gap between pass@k and pass^k is where your eval infrastructure lives. An agent that CAN produce good output but WON'T do it reliably is the exact problem eval loops solve.
Why This Matters Now
The AI Evals Flywheel from Chapter 6 now has teeth. Scorecards, correction routing, shared vocabulary. The pieces fit together.
Evals are not QA. They are system architecture.
The eval loop is the inner loop. In June 2026 the field started calling the outer cycle loop engineering, designing a system that runs an agent until a goal is met instead of prompting it by hand. That outer loop is only as good as what checks each pass. The eval loop is that check. Loop engineering gets the headlines, but a loop without an eval inside it just ships unverified work faster. The verifier, not the model, is the bottleneck.
I keep thinking about that enterprise KRI. It wasn't surveillance. It was governance. It made the invisible visible. It turned measurement into action. It routed problems to the people who could actually solve them. Evals for agent systems serve exactly the same purpose. They don't just tell you if output is good. They determine what happens next.
Getting started is simpler than it looks. Identify one high-risk dimension in your agent's output. Choose one grader type that can measure it. Define one correction path for when it fails. Run that for a sprint. You will learn more from one real eval loop than from a month of planning the perfect scorecard. Everyone else will discover their quality problems from their customers.
What's Next
Evals judge agent output at the system level. But what about the developer sitting with the agent, deciding in real time whether something is good enough to proceed? Chapter 10 covers Test-Driven Development for Agents, where tests become the specification language and the human becomes the implicit eval. The shift is from system-level judgment to developer-level specification.
Whoever designs the eval is programming system behavior.
